Unidata Internet Data Distribution (IDD) Plan
Ben Domenico
June 23, 1994
Overall Goal
The primary goal of the IDD is to deliver data reliably to networks of
computers at the sites of participants. The receiving sites specify the
data of interest and the IDD delivers those data sets to the local site as
soon as possible after the data sets are available from the source.
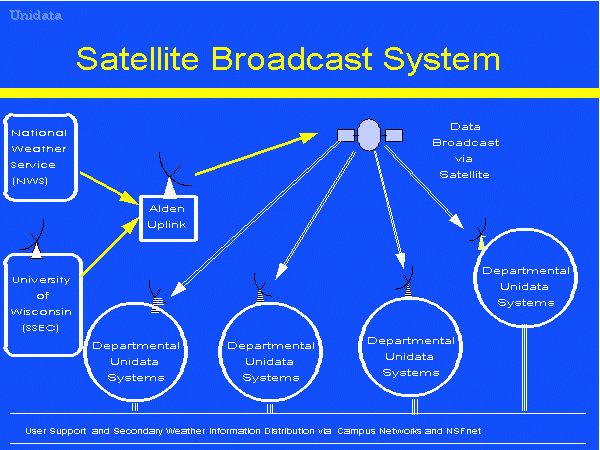
The initial Unidata system for data delivery, is shown in
the
 Satellite Broadcast System
diagram, where as the new Internet-based approach is illustrated
in
Satellite Broadcast System
diagram, where as the new Internet-based approach is illustrated
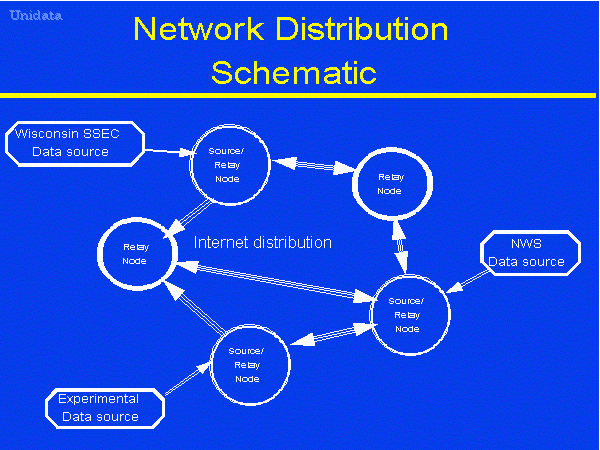
in
 Network Distribution Schematic.
Network Distribution Schematic.
The diagrams show that, with the IDD approach, any site on the
network can become a data source. Consequently it's easier for
members of the community to experiment with new sources of
data.
Philosophy
The Unidata community as a whole is working together to build an
Internet Data Distribution (IDD) System for disseminating real-time
environmental data. The Unidata Program Center is planning the system,
coordinating the efforts of the participating organizations, and
developing key software components. However, it is the Unidata
community of universities and associated organizations who are building
and will run the IDD network.
Underlying Principles
The Internet Data Distribution (IDD) system is a means by which Unidata
universities can build and keep current their holdings of environmental
data, especially those updated in near-real time. IDD is a "distributed
application," with interacting components (data sources, data relays, and
data sinks) at many locations nationwide. Responsibilities for running
and maintaining the IDD system also are distributed, on the assumption
that proper balances among cost, data needs, performance, and flexibility
are best achieved through community effort--organized and guided by the
Unidata Program Center (UPC)--rather than a more centralized endeavor.
Elaborated in Underlying Principles of the
Unidata Internet Data Distribution (IDD) System by Dave Fulker are
eight key principles that reflect the above purpose and underly the IDD
system design:
- Data Reception Implies Relay Responsibilities
- The UPC Acquires Data of Very High Interest
- The UPC Chooses Routes for High-Interest Data
- Routing Is Ad Hoc for Data of Lesser Interest
- The High-Interest Category Is Defined by Actual Use
- Incentives and Criteria Exist for High-Level Relays
- The LDM Design Facilitates a Community Endeavor
- The Internet Will Evolve to Simplify the IDD
In
LDM 4.1 Plans ,
Russ Rew provides current plans for the LDM 4.1, which
is currently being field tested.
Distinguishing IDD Characteristics
The fact that the Unidata IDD is a community undertaking has
been described in earlier sections. Another distinguishing
characteristic of the IDD is its approach to making
data available via the Internet. In the following sections, the
IDD is described as a subscription service designed to
get data whose value diminishes with time to end users
as quickly as possible.
The Unidata IDD: a Subscription Service for Perishable Data
What distinguishes the Unidata IDD from most other Internet-based,
data-distribution systems is that the IDD allows the end user to specify in
advance which data sets should be delivered to his/her local computer
network, and it delivers those data as soon as possible after they are
available. The system can be thought of as a data subscription service. An
analogy in the print media would be a newspaper or magazine delivery
subscription. Subscribers know ahead of time they'll be interested in at
least a certain percentage of the information from a set of sources and
want that information delivered to their premises as quickly as possible
and on a regular basis.
The print analogy falls short in
that the IDD affords much finer granularity than the typical newspaper
or magazine subscription; it's like subscribing at the level of
articles within the magazine. Furthermore,
the term subscription is being used here describes the mechanism for
accessing the data; it does not imply a charge for the data in this
context.
Data Servers and Data Archives
Other data provision services are more analogous to newspaper stands,
bookstores, libraries, and archives. In these cases, the provider
assembles a collection of information that might be of interest and the
client peruses what's available before deciding what to "bring home"
for further study.
Electronic Data Delivery Alternatives
Different mechanisms for providing information are not mutually exclusive.
In fact they coexist nicely in the world of print media and serve to
complement one another. The same holds true for electronic delivery
systems: different systems can and should coexist. Current systems
include long-term archives, such as those at NCAR, NCDC, University of
Wisconsin SSEC, the EROS Data Center and others and FTP data servers, such
as those at NMC, the SSEC (the Unidata /Wisconsin data recovery system),
and the servers with satellite observations being set up at NASA Ames.
There is also a need for a data delivery subscription service such as the
Unidata IDD.
The different delivery approaches are illustrated in the
schematic diagrams:
As the
 Hybrid Approach
Hybrid Approach
diagram shows, the Data Center administrator could make
use of the IDD to populate the data center archive with the
latest data products from a variety of observing systems.
Likewise, end users could subscribe to certain products so
that they would be delivered to the local system as soon
as they arrive at the data center.
The IDD approach can be thought of as "pushing" the data from the
source to a number of subscribers whereas a data server or archive site
allows the user to pull the data from the holdings. One can imagine
cases where a subscription delivery service like the IDD could be used
to populate data servers and archives or to take data from an archive
or server and deliver it to a set of subscribers automatically. The
different mechanisms for data delivery do indeed complement one
another.
Moreover, the IDD can push the data not just into local
holdings but also into local processes, thus supporting the creation of
transformed or value-added data streams (in real time) or the tailoring
of local holdings in unlimited ways.
Scope
This section provides a general description of the scope of the IDD
undertaking in terms of the primary data sets involved and who the
community of users will be. More detail about particular data
sets--particularly those that will be introduced into the system at later
stages--is contained in separate documents pertaining to those particular
data sets.
Data Sets
The initial focus of the IDD is on reliable delivery of the data currently
being
delivered to sites via the Alden satellite broadcast system. These are the
Family of Services datastreams and the Unidata Wisconsin channel. In
October, the FOS datastreams will increase in speed so the primary
datastream speeds are as follows:
Primary Datastreams:
Before October Starting
October 1994
Datastream bits/second bits/second
Unidata/Wisconsin Channel 9,600 9,600
Domestic Data Plus (DD+)* 4,800 19,200
Domestic Data Service (DDS) 2,400 9,600
Public Products Service 2,400 9,600
(PPS)
International Data Service 2,400 9,600
(IDS)
High Resolution Datastream 19,200 56,000**
(HRS)
Total for Unidata 36,000 94,000
datastreams
* Via the current satellite system, most sites subscribe to DD+ which
is a combination of DDS and PPS. Using the IDD, the PPS and DDS will be
transmitted separately, but can easily be combined by the LDM software
at the receiving site.
**The change to 56 kbits/second for the HRS is not entirely specified at
this time. With current workstation technology, it will not be possible to
ingest a 56 kbit/sec stream on an asynchronous serial port.
Thus the primary datastreams currently have a peak rate of 36
kbits/second. In October that will increase to 94 kbits/second.
The routing for delivering the primary, high-interest datastreams
as soon as possible after the product are available
is shown in
 IDD ASAP Delivery System .
IDD ASAP Delivery System .
To gain experience with other, experimental data sets, the system has
been shown to work in creating mirror sites for processed products such
as those produced by the BlueSkies system at the University of
Michigan and with high-volume datastreams from the Forecast
Systems Laboratory. Use with other experimental datastreams from the
National Meteorological Center is also anticipated.
Next in order of priority are the NIDS data for sites which decide to
purchase some of the NIDS options from WSI.
Experimental data sets from NMC and FSL are next on the agenda. It now
appears that data sets that we had originally thought would be coming
from FSL (e.g., the MAPS data) may now be routed through NMC. This in
turn means that we'll have to develop a system for accessing the data
from the FTP servers at NMC and then injecting them into the IDD. The
NMC FTP front-end access is an element of the system we are trying to
get one of our sites to develop. As time permits, we'll encourage NMC
to install an LDM source system at their site as we had originally
planned.
Finally, as we learn more about NOAAPORT and AWIPS, we will incorporate
plans for introducing some of those data into the IDD system if they
are of interest to the community.
Size of the User Community
Ultimately the entire community of Unidata university sites and
affiliates will be involved in the IDD system. This group, which
currently totals approximately 130, includes some sites that are
currently only running OS/2 systems. It also includes source sites such
as Alden, WSI, and the SSEC, as well as some of the regional network
providers. Merit is the only network provider at present, but
Northwestnet, Westnet, SURANet, and NEARnet have also been involved in
some of the discussions.
Network Structure
General Description
In general, any site on the Internet can inject data into the IDD. In
order to make the system scale for use with a large number of sites, a
fan-out design is used. That is, the data are sent from the "source
site" to a limited number of downstream "relay" nodes, which in turn
relay the data to another set of nodes until the products in the stream
reach their destination at "leaf" nodes. For each data source site
there is a routing structure (sometimes called a topology) that
determines which relay nodes get the data from the source and where the
data are relayed beyond that point.
Viewed as a data delivery
subscription service, the IDD consists of the following components:
- a language in which the end user can specify which
data are of interest (the LDM pattern/action configuration),
- a mechanism at the data source for injecting the data
into the delivery system as it becomes available (an LDM ingestor),
- a delivery system which is capable of getting the data
from the source to the end user sites reliably (the LDM 4.1 server), and
- a delivery system which scales as the number of subscriber
sites increases ( the IDD fanout routing design). Since the
end user of the IDD is specifying data needs ahead of time,
the system is designed to deliver those data reliably for
an increasing number of users. In contrast,an archive
or data server system may simply limit the number of users
who can access the information at any given time. Indeed, this
is what happens to certain weather information servers
during periods of severe weather.
Data Fan Out from the Source
To address the issue of scalability, the IDD is designed with a set of
relay nodes that move the data from the source site to a fixed number
of top-level relay nodes; these relays in turn move the data to end
user sites or to a second level of relay nodes. The diagram
 Data Fanout
Data Fanout illustrates this
principle. The main point is that
number of downstream nodes served by a relay is fixed, so the system
scales with the number of end user or leaf nodes if:
- a sufficient number of relay sites can be set up,
- computer systems at relay nodes are sufficiently reliable
- the network connections between nodes is sufficiently reliable,
- the software used for moving the data can deliver data
reliably in the face of typical problems with computer
systems and the underlying networks.
The IDD fan-out approach hinges on the assumptions about relay nodes.
The fan diagram may be different for different data sources, but the
principle remains the same.
Relay Nodes
Relay nodes do the bulk of the work in the IDD system. They are responsible
for capturing products from an upstream node and reliably relaying them to
a set of downstream nodes. While there will be a limited number of nodes
directly below them, some of these may themselves be relays who in turn
send the data to leaf nodes. Thus there can be a large number of sites
depending on a given relay node (directly or indirectly) for their data.
Source Sites
Source sites are different from relay nodes in that they do not
get data from an upstream LDM. Source sites
will each run a special ingester for each datastream they inject into
the system. The ingestor feeds the data into an LDM server which in
turn fans the data out to a set of top-level relay nodes.
Leaf Nodes
Leaf nodes capture data from an upstream LDM, but do not relay them
further. Thus an IDD leaf node has fewer responsibilities than relay or
source nodes. If a leaf node system fails, only the local users are
affected. On the other hand, a leaf node is dependent on having all the
upstream relays working properly.
OS/2 Only Sites
Since the LDM server software runs only on Unix, sites that do not have
Unix systems will function only as leaf nodes. Thus any sites having only
OS/2 computers running McIDAS will function as leaf nodes. Special plans
are being made to insure that these sites will be able to access data via
the IDD.
The options under study include:
- having the upstream node run special software (similar to
Mctingest) that will feed the data directly into the
network data access facilities which are an integral part of McIDAS OS/2
- porting at least the data capture portion of the LDM
to OS/2 so the OS/2 computer can function directly as an IDD leaf node
- developing a simplified "IDD in a Box" implementation of
the LDM server running on a specific PC hardware configuration
which can be installed at a site with minimal Unix expertise.
More detailed plans for dealing with OS/2 only sites and for
"IDD in a Box" systems are in a separate document
McIDAS-OS2 IDD Leaf Node Implementation Plan
by Tom Yoksas.
Data Recovery Sites
The catastrophic data recovery system will consist of a few selected sites
capturing the data and storing them in predetermined files where other
sites can access them via restricted FTP. This system will be available for
sites when automatic rerouting of data fails. A site whose data-access
computer fails over a weekend, for example, will have somewhere to turn to
recover missed data sets.
The model for these sites is the Wisconsin SSEC system which has served
as a data recovery site for the Unidata/Wisconsin channel for several
years.
Data Recovery Site Planning
by Russ Rew provides more information about:
- naming conventions and file system layout
- mechanisms for restricting access
- resources at each data recovery site, as well as
- options for improving data reovery sites during testing and deployment.
Network Administration Centers
Even though the IDD is being run as a community project, with much
of the responsibility being distributed among the participating
institutions, there is still a need for certain centralized
administrative services. The most obvious of these are:
- the traditional support roles of training, consulting,
documentation, and software updates
- signing on new participants
- monitoring the performance of the system
- specifying data routing
- specifying needed system reconfigurations and updates
- providing information about the system as whole.
There will be several network administration centers. For the
initial high-interest datastreams:
- The UPC will maintain central logs of overall system
performance.
- WSI will maintain central control of NIDS sites, since
those sites will have to subscribe to and pay for that
service with WSI. WSI will also monitor the delivery
system for NIDS data.
- The UPC will determine who participates in the
distribution of Family of Services and Unidata/Wisconsin
channel data, but Alden will monitor the distribution of
the FOS datastreams and take whatever remedial actions are
possible in the event of problems--using administration
software provided by the UPC.
A more detailed description of the monitoring and administrative systems
are provided in
IDD Statistics Monitoring System
by Robb Kambic.
The current IDD reliability statistics are available via
ldmstats.nodes.
Operational Modes
Normal Operation
It will be possible to maintain different distribution hierarchies for each
datastream. Initially, however, the FOS streams and the Unidata/Wisconsin
channel will probably have the same set of relay nodes. The NIDS routing
will be distinct since not all the NIDS data will go to all sites. Each
site in the system will be assigned a primary and alternate source for each
datastream.
Source Site:
In general, any site on the Internet will be able to inject data into the
IDD. In order to make the system scale for use with a large number of
sites, a "fan-out" design is used. That is, the data are sent from the "source
site" to a limited number of downstream "relay" nodes, which in turn relay
the data to another set of nodes until the products in the stream reach
their destination at "leaf" nodes. For each such data source site there is
a routing structure (sometimes called a topology) that determines which
relay nodes get the data from a source and where the data are relayed
beyond that point.
Top-level Relay Nodes:
The top-level relay nodes take the data from an LDM server or from an
ingestor at the source site and relay the products to a fixed set of
downstream relay and/or leaf nodes. Top-level relay nodes must access
all the data that downstream nodes subscribe to, even if they do not
use all the data locally.
Secondary Relay Nodes:
These are like the top-level relays except that secondary relays take the
data from an upstream relay node LDM rather than from a source site. Again
they must subscribe to all the data that downstream nodes have subscribed
to.
Leaf Nodes:
These are sites that only receive data from an upstream relay; they have no
responsibility for relaying the data to other sites. Consequently, they
subscribe only to those data set they need locally.
Data Recovery Sites:
Some sites, preferably those higher up in the fan hierarchy, will be
responsible for maintaining a short-term archive of the data to be used for
data recovery. At least initially, the UPC anticipates that data will be
recovered by a mechanism other than the LDM/IDD; FTP servers are
being used at data recovery sites during the IDD field test.
Network Monitoring and Administration
During normal operation, the overall performance of the IDD will be
monitored at the UPC and at those source sites that are staffed around the
clock. The UPC will also maintain the system that determines the
distribution topology for the primary "supported" datastreams. By this we
mean that the UPC will assign primary and secondary upstream nodes for each
new site and will maintain the topology tables that define the primary
network topology and alternatives.
Degraded Mode Operation
Failure Modes and Remedies
There are several ways the overall system can fail, and there are
different mechanisms for dealing with the various failures.
Source Site Failure:
The failure of any component of the system at a source site means that
the entire system fails. Hence it is especially important that
redundant systems, power backup facilities, and alternate network access
points be available at source sites.
If source sites are also configured as data recovery sites, however,
it's possible to recover from failures of the sort where the source
site succeeds in capturing and storing the data locally but fails to
get the data into the IDD system in real time. This might happen, for
example, if the connection to the Internet failed for a period of
time.
Relay Node Failures:
Each secondary relay node and each leaf node in the network will have a
primary and secondary upstream node for each datastream. In the event
that the primary upstream node fails, the LDM software will
automatically switch over to the alternate upstream node after a
specified period of time. There is no provision in the LDM 4.x for
automatically recovering the data lost from this kind of failure. Such
facilities are part of the LDM 5 protocols. A more detailed description
of failure mode operations is provided in
Internet Data Distribution Administration by
Robb Kambic.
Depending on how quickly the switch over can be accomplished, some data
will be lost. Consequently the affected relay node and all downstream
nodes will have to turn to a data recovery site to fill in the missing
data.
Leaf Node Failures:
If the leaf node LDM machine fails, the site simply accesses missing data
from a data recovery site.
Difficulties with the Underlying Network:
This is the type of failure over which we have least control. Assuming
that participating university departments will be using the whatever
networking infrastructure has been put in place for the campus, it may
be difficult to build in the redundant computer systems, alternative
network paths and power backup for all relay nodes. By attempting to
get as many relay nodes as possible into operational settings such as
those at regional network operations centers, some of this redundancy
will be available. This will be especially important for the top-level
relay nodes and data-recovery sites.
Despite the lack of redundancy, early experience with the LDM 4.1 is
very encouraging. It appears that the product queuing version of the LDM
can deliver data reliably over highly congested and unreliable Internet
segments. The trade-off is that the data may arrive later than they otherwise
would have, but they will get there. Given the product queue sizes
being used in the test, it appears the LDM 4.1 delivers data reliably in
the face of network outages that last a significant fraction of an hour.
More careful monitoring is needed to confirm this, but the early
results are very hopeful.
Catastrophic Data Recovery
As noted above, there will be data recovery sites that will maintain about
a week's worth of data. The ability to access data at these sites should
cover most situations, such as where a data ingest system fails overnight
or over the weekend and a professor needs certain data sets for an early
morning class.
IDD Requirements Specification
The long-term requirements for the IDD system are described in
Unidata IDD Functional Requirements
Specification by Dave Fulker.
System Components
Organizational
The various roles IDD sites can play (source, relay, or leaf node and being
an administrative or data recovery center) are described
in more detail in Mitch Baltuch's
IDD Site Operational Requirements .
Software
LDM
Certain key changes have been incorporated into the LDM 4.1 release,
the most important being the incorporation of a product
queue that will "buffer" a large number of products at a source or
relay site. At present, the product queues hold about an hour's worth
of data. The product queue enables the LDM to deliver data reliably in
the face of rather severe network congestion and most of the common
network failures.
There is also a new architecture
that invokes separate processes to read each incoming data stream and
write the products into the queue and processes to read
from the queue and send the products to each downstream node. The new
architecture obviates the slow-link problem--now each downstream
node will get data as fast as it can absorb them. One slow link will
not have an impact on the other downstream nodes.
A more detailed document on the
LDM 4.1 has been written by Russ Rew.
Administrative
Details on the administrative software can be found in
Internet Data Distribution Administration by
Robb Kambic.
Hardware and Networking
Hardware and networking requirements for sites
are described in Mitch Baltuch's
IDD Site Operational Requirements .
Data Access
Gaining Data-Access Agreements.
Generally this is being handled at the UPC by Dave Fulker, Ben
Domenico, and Linda Miller. There may be special cases where others
would make the arrangements. For example, sites in specific states may
make arrangements for accessing pollution data available in
state data banks.
Payments for Data
Currently there are three approaches for obtaining data:
- The UPC negotiates a quid-pro-quo involving data
access rights in exchange for participation in the program.
Several organizations have expressed interest in this--
they would provide their data if they turn could become
part of the IDD and have access to other data where appropriate.
No specific agreements of this nature have been arranged to date.
- The UPC negotiates an agreement where a central fee is paid
that provides free access for all participants. The current
agreement with Alden for access to FOS data via the IDD is an example of
this type of arrangement.
- Individual sites make specific arrangements with a vendor
for access to certain data sets. In this case, the UPC may
play a role in negotiating special pricing for the community
as a whole. The contract with WSI for IDD NIDS data is an
example of this type of agreement.
Implementation Plan
The UPC plans to continue with the IDD field test through August 1994. This
will involve a limited number of sites (between 24 and 36). This is a
number that we feel is manageable in a test setting where changes in
software, routing, and administration are made quite often. We intend that
most of the relay nodes will drawn from the group of field test sites. By
the end of August, we should have a solid, well-tested system and a set of
experienced sites who can form the core of the relay infrastructure for the
subsequent deployment. Specifically, we hope to have 30 sites running by the
end of August with 5 at the top level relaying to 25 at the next level.
These in turn could relay the data to 125 sites which should cover our
current community of users. Linda Miller is developing the deployment plan.
The latest version is in
Unidata IDD
Participation Deployment Plan .
Source Sites
Present testing is focused on the datastreams that are currently
disseminated via the Alden satellite broadcast, namely, the Family of
Services and Unidata/Wisconsin channel. Thus the initial high-interest data
sets will come from source sites at Alden and University of Wisconsin
SSEC. The source for NIDS data will be WSI. Additional experimental
data sets with special distribution routing are being set up experimentally
and independently from the mainstream IDD for lightning data from SUNY
Albany and BlueSkies processed products from University of Michigan.
Relay Nodes
Most of the field test sites have been chosen with the
understanding that they would become relay nodes if the test indicates
that's feasible.
LDM Development
The next major release of the LDM--LDM 5--is being planned based on our
experience with the IDD field test. The specifications for the LDM5 are
in
Unidata IDD Functional Requirements
Specification by Dave Fulker. See
LDM 4.1 Plans .
by Russ Rew for information on the LDM 4, which is currently
being tested.
Field Testing
As noted above, field testing includes not only the LDM software
system, but also the cooperative management system and the supporting
systems for performance and configuration monitoring and
administration. These systems are described in more detail elsewhere,
but the main idea is to limit the scope of the IDD to about 30 sites
during the test period so all parts of the system can be updated and
changed rapidly and so problems uncovered can be corrected. The test
period will produce a robust software system, a tested administrative
and management system, and an experienced set of relay nodes.
The current field test routing topology is show in
 Field Test Routing.
Field Test Routing.
Deployment
Our target is to deploy the system to the entire community within a year
after completing the field test. This means that we'll have to bring about
8-10 new IDD sites online per month during the deployment period. More
details regarding widespread implementation are in
The Unidata IDD Participation Deployment Plan by
Linda Miller.
Site Selection Criteria
The primary criteria for selecting new sites
are:
- Unix system administration expertise
- Bandwidth to the Internet
- Relationship with regional network provider
- Local hardware resources
- Local system administration resources and expertise.
A site survey is underway, and Linda Miller and Mitch Baltuch are
setting up a selection criteria matrix to assign points
to each site in each category. The resulting total for each site will
provide a mechanism for establishing an order in which the sites will be
brought online.
Sites with little or no Unix and networking experience will find the
transition to IDD most challenging. Two approaches to alleviating the
problems for these sites are being investigated: IDD in a Box and
Mctingest.
IDD in a Box
Part of the problem for sites getting started with the IDD is
administering a Unix system on which to run the required LDM
software. One solution might be to build an LDM
system on a fixed, inexpensive Unix platform with limited
capabilities. By limiting the Unix functions, the user has to
deal only with those needed to run the LDM software, which would
greatly simply systems administration. If such a
system is capable of handling the throughput needed for a relay
site, it might prove to be a low cost method for creating relay nodes
using sites do have more expertise and staff. More details on
this approach are in an article
McIDAS-OS2 IDD Leaf Node
Implementation Plan by Tom Yoksas.
Plan for OS/2 Only Sites
Sites which currently only run OS/2 systems have no system on which to run
the LDM software in order to capture the data from an upstream IDD node.
While IDD in a Box might be one solution, the UPC is also investigating the
possibility of adapting a software called Mctingest. Mctingest has proven
reliable in transporting data via the Internet to downstream nodes running
McIDAS OS/2 and McIDAS/X. It has some of the functions of the LDM4.1, but
it uses the TCP transport built into the current versions of the McIDAS
systems themselves. It may be possible to use Mctingest on an upstream IDD
node to send the Unidata/Wisconsin datastream to a downstream node running
McIDAS but no LDM.
A third possibility is to implement a receiving system that would use the
LDM protocols to capture the Unidata/Wisconsin channel on McIDAS computer
without using the full LDM implementation. These options are described in
more detail in Tom Yoksas's paper
McIDAS-OS2 IDD
Leaf Node Implementation Plan .
 Satellite Broadcast System
diagram, where as the new Internet-based approach is illustrated
in
Satellite Broadcast System
diagram, where as the new Internet-based approach is illustrated
in
 Network Distribution Schematic.
Network Distribution Schematic.
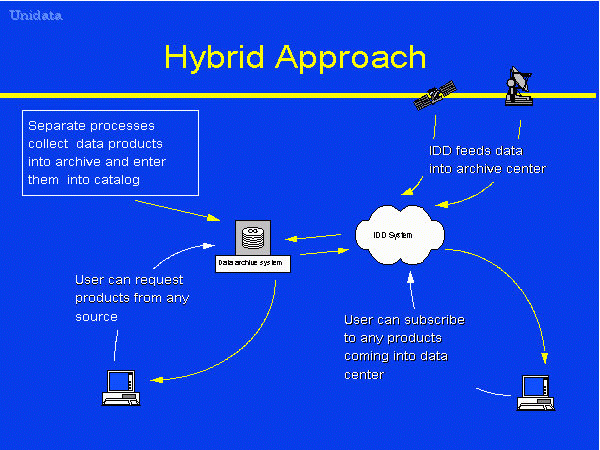 Hybrid Approach
diagram shows, the Data Center administrator could make
use of the IDD to populate the data center archive with the
latest data products from a variety of observing systems.
Likewise, end users could subscribe to certain products so
that they would be delivered to the local system as soon
as they arrive at the data center.
Hybrid Approach
diagram shows, the Data Center administrator could make
use of the IDD to populate the data center archive with the
latest data products from a variety of observing systems.
Likewise, end users could subscribe to certain products so
that they would be delivered to the local system as soon
as they arrive at the data center.
 IDD ASAP Delivery System .
IDD ASAP Delivery System .
 Data Fanout illustrates this
principle. The main point is that
number of downstream nodes served by a relay is fixed, so the system
scales with the number of end user or leaf nodes if:
Data Fanout illustrates this
principle. The main point is that
number of downstream nodes served by a relay is fixed, so the system
scales with the number of end user or leaf nodes if:
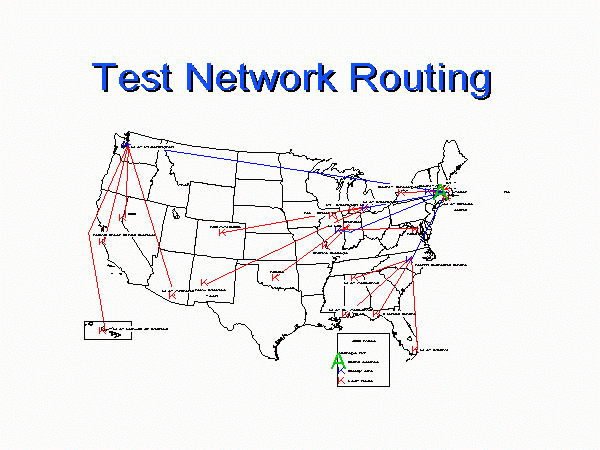 Field Test Routing.
Field Test Routing.

